
高雄市 1999 智慧分案系統:利用機器學習分類案件
高雄市 1999 提供了至少 7 年的歷史資料,我們是否可以透過分析這些資料,供未來進行快速分案呢?
繼上一次的 高雄市 1999 市政儀表板:用 Open1999 開放資料做視覺化 後,我們在同一個比賽中其實還做了智慧分案系統:終極目標是案件受理人員只要把案件描述打下來,系統就可以自動分案,把案件分派到適當的局處。
下載、預處理 1999 歷史資料
在高雄市政府資料開放平臺中,有從 100 年到 106 年度的歷史派工資料,首先我們透過平臺上的 CKAN API 搜尋並下載下來,這邊使用的是 node.js 中的 axios 套件。之後再透過 concat-files 套件把所有的檔案(CSV 格式)結合成同一個檔案,以供後續進行分析。
觀察這些檔案格式後,由於我們透過案件描述來預測局處,所以我們主要會分析 BeforeDesc 欄位及 UnitName 欄位。
預處理的部分,一開始我們先將 BeforeDesc 中的描述斷詞,當然是使用 jieba 套件。在這裡我們還把一些可能會影響預測的贅詞去掉,像是受理人員會記錄的「渠反映該處......」、「......建請會同查處」等等,另外我們也把車牌去掉了。斷詞後會得到這樣的資料:
有人 放鞭 鞭炮 放鞭炮
民 眾 施放 鞭炮 妨礙 安寧
施 方 鞭炮 妨礙 安寧
* 渠 反映 該 業者 音樂 樂聲 音樂聲 大 , 妨害 安寧
擴音 擴音器 聲 大 擾民
一間 PUB 音樂 樂聲 音樂聲 過 大 , 妨礙 安寧
多名 青少 少年 青少年 在 施放 放煙 煙火 放煙火 施放煙火 , 妨礙 安寧
店家 客人 喧鬧 , 車輛 紅線 違停
渠 反映 該 業者 歡唱 音量 過 大 , 妨害 安寧
店家 冷氣 水塔 聲 大 擾民
音樂 樂聲 音樂聲 大 擾民
......
其實在這種資料裡出現車牌似乎有點不應該,大概是沒注意到這裡也要去識別化吧?
接著要將這些詞彙整理出來,並計算出現的次數:
路燈 121218
不亮 116759
故障 110524
反映 96978
一盞 59342
路面 55458
噪音 42758
坑洞 40246
號誌 38908
......
訓練預測模型
預處理完資料後,接著就是要開始訓練模型了。樣本數目大概有 52 萬筆資料,整理出來大概兩萬個詞彙吧,我們在這裡選擇使用類似貝式分類的方法來訓練模型。
我們將每一個詞彙在不同局處出現的機率記下來,例如路燈這個詞在各個局處的機率:
養工處 0.8995116236862513
環保局 0.029484070022603903
警察局 0.000057747199260835846
水利局防洪維護科 0.002656371165998449
交通局 0.0005362239931363329
台電公司 0.001229190384266363
養工處2 0.04199046346252207
觀光局 0.0013199359831048195
民政局 0.00006599679915524098
區公所 0.0011384447854279067
工務局 0.00014024319820488707
動物保護處 0.00006599679915524098
自來水公司 0.000008249599894405122
而不亮這個詞:
養工處 0.8247843849296413
交通局 0.11998218552745399
水利局防洪維護科 0.0046677343930660595
養工處2 0.036476845468015315
台電公司 0.0004967497152253788
警察局 0.000008564650262506531
民政局 0.000034258601050026125
觀光局 0.002192550467201672
區公所 0.0013360854409510188
工務局 0.00005138790157503918
以此類推,我們將每個詞彙在不同局處的機率都算出來並存下來。
我們並沒有深入了解派工的邏輯,所以不清楚為什麼有些事件會派給大樹區公所、大寮區公所等等公所。為了簡化計算,我們將所有區公所統一用「區公所」來計算;此外,我們也沒有去深入了解為什麼會有養工處和養工處2。
使用、評估預測模型
有了這個機率模型後,之後輸入新的句子,一樣都會先透過結巴斷詞,分解出各個詞彙。透過剛剛的預測模型算出每個詞彙在不同局處的機率,並將不同局處的機率相乘起來(若該詞彙沒有紀錄,則忽略不計)。
例如當輸入「路燈不亮」這個詞,首先會被斷為「路燈 / 不亮」,接著透過剛剛的模型算出兩個詞在各個局處的機率,並相乘而得到:
養工處 0.7419031412791277
環保局 0.029484070022603903
養工處2 0.0015316796468527608
動物保護處 0.00006599679915524098
交通局 0.0000643373266287557
水利局防洪維護科 0.000012399235052279951
自來水公司 0.000008249599894405122
觀光局 0.0000028940262564327704
台電公司 6.105999733420899e-7
......
如此我們便能預測「路燈不亮」應該交給養工處、環保局或養工處2。由於輸入的句子越長,斷開的詞就會越多,機率就會越乘越小,在這裡我們只選出最大(或前幾大)的局處當作候選局處。
把他丟回這 7 年度的資料預測看看,可以看到模型準確率和案件量呈正向關係,前幾名大概如下:
| 部門 | 案件量 | 預測準確量 | 準確率 |
|---|---|---|---|
| 養工處 | 200,888 | 197,833 | 98% |
| 環保局 | 171,650 | 163,704 | 95% |
| 交通局 | 36,779 | 33,891 | 92% |
| 水利局防洪維護科 | 44,868 | 38,988 | 87% |
| 警察局 | 24,679 | 19,276 | 78% |
| 動物保護處 | 9,220 | 5,409 | 59% |
由於我們使用 100~106 年度的資料訓練,所以我們改拿 107 年 1 月到 107 年 4 月底的資料來做評估。前幾名如下:
| 部門 | 案件量 | 預測準確量 | 準確率 |
|---|---|---|---|
| 養工處 | 12,550 | 12,290 | 98% |
| 環保局 | 13,590 | 13,037 | 95% |
| 交通局 | 2,456 | 2,907 | 85% |
| 水利局防洪維護科 | 3,216 | 2,669 | 83% |
| 警察局 | 1,883 | 1,196 | 64% |
| 動物保護處 | 904 | 505 | 56% |
結語
最後將這模型做成 API 以供分案系統直接在線上呼叫使用,一樣把成品丟出來放在這裡:https://work1999.noob.tw。
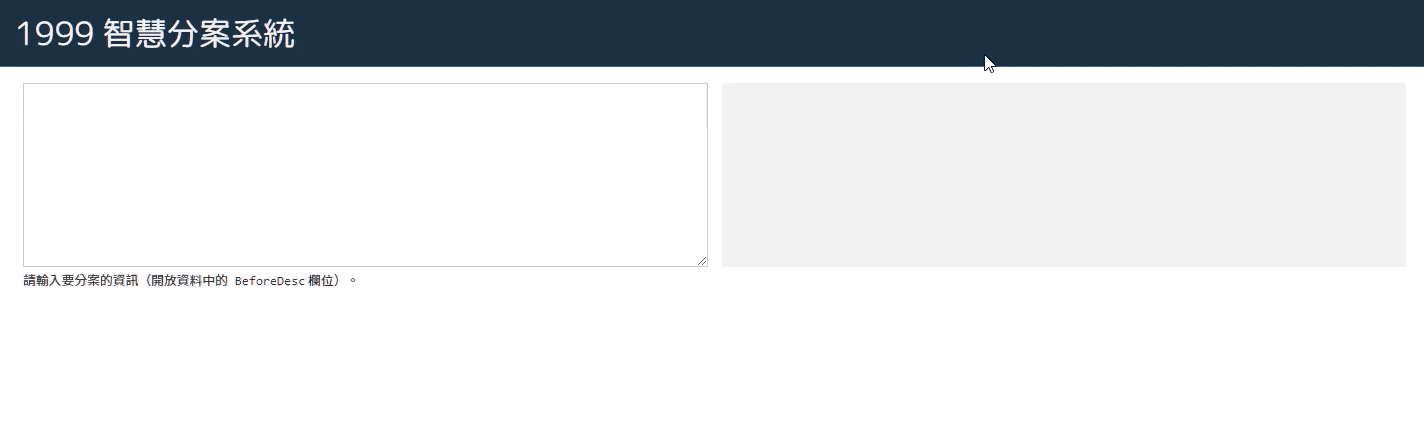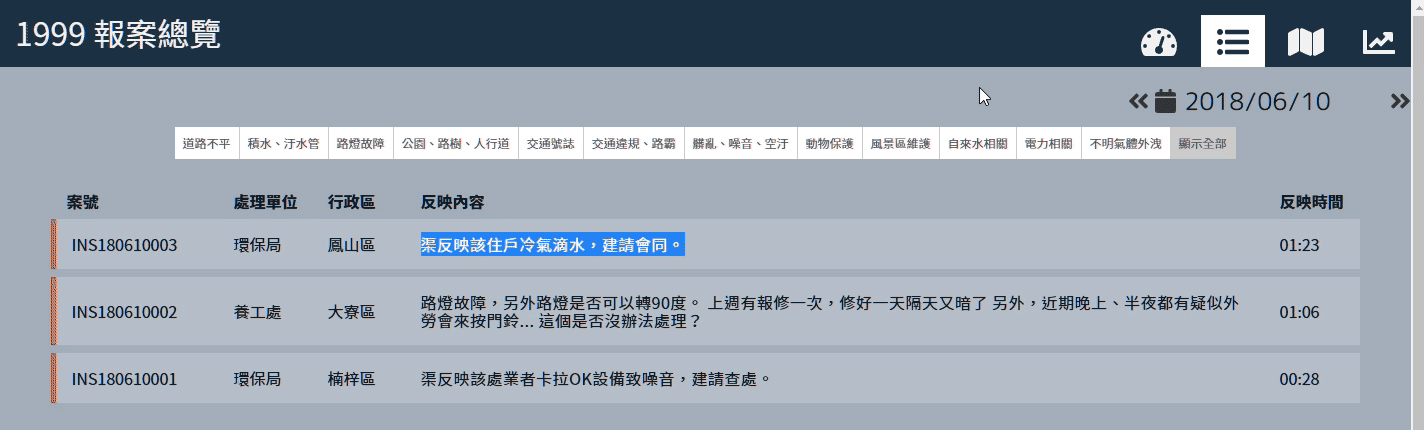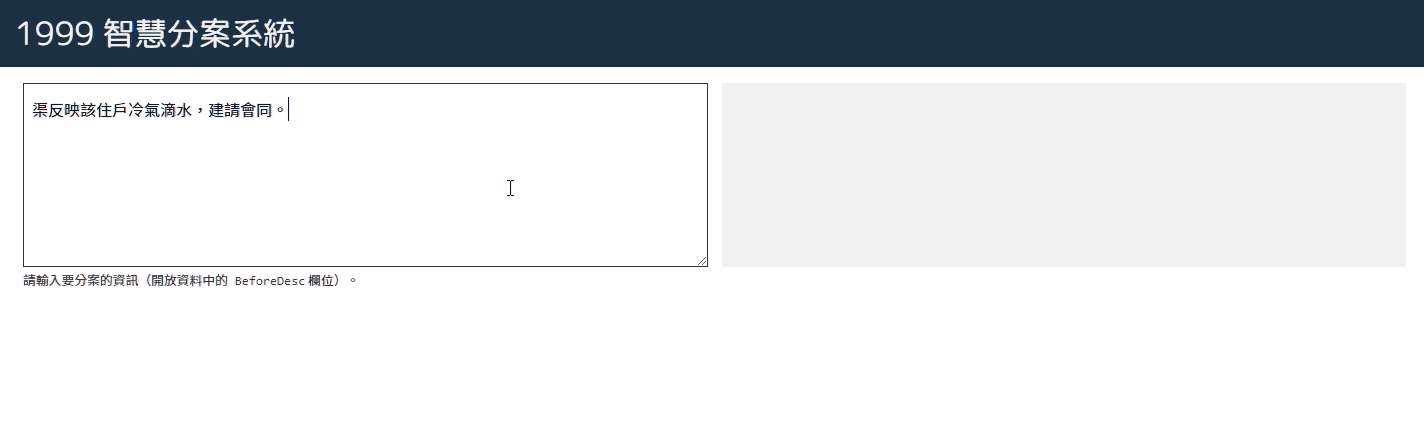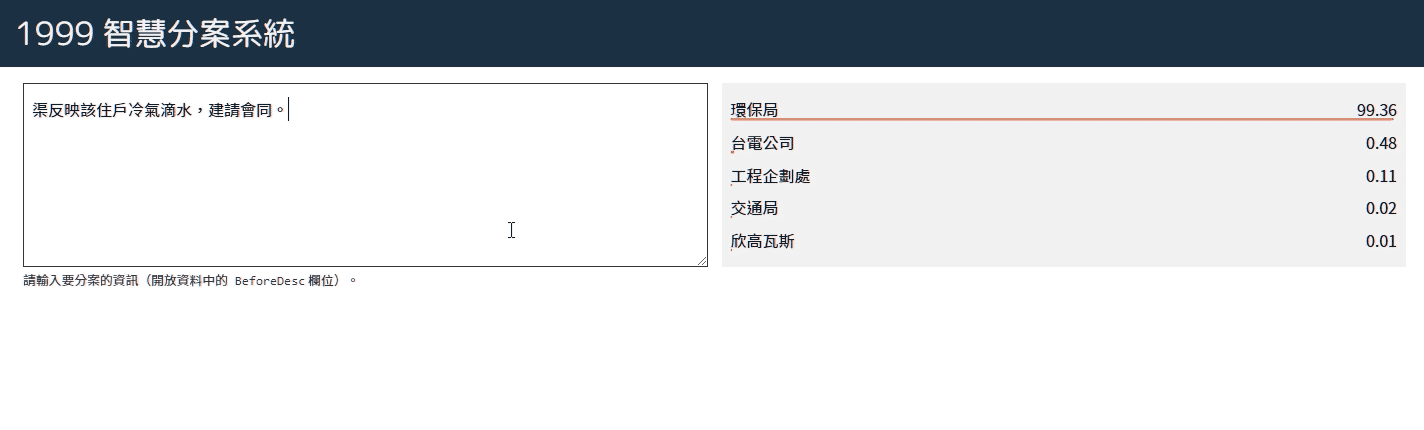
最後做出來的智慧分案系統看起來很厲害,也實際能操作,不過某些某些描述丟進去還是沒辦法準確預測;像剛剛說的 107 年資料丟進去,完全命中的機率大概有 78%,而考慮前三名的局處的話命中機率有 90%。雖然還不能完全取代真人判斷,但至少可以協助判斷,是個還算堪用的模型了。未來是否有人能建議該怎麼改善或用不同方法算算看呢?也許可以考慮看看 NN?
噢,你說比賽結果如何?
我們得銀質獎啦(哼),輸給區塊鏈啦(哼)。