Elasticsearch:一套資料搜尋分析系統
最近接觸了 Elasticsearch 這套系統,它能夠以 JSON 的形式儲存資料,並且去做即時的分析和搜尋。那它和 MySQL 資料庫有什麼不一樣呢?
MySQL 屬於 RDBMS 的資料庫,但 Elasticsearch 比較算是搜尋引擎,而且 Elasticsearch 的安裝簡單,可以透過 HTTP 並使用 JSON 來處理資料。
![]()
概念釐清
由於 Elasticsearch 和一般 RDBMS 架構不同,所以在名詞上也不太一樣。和 MySQL 比照的話大概是這樣:
MySQL:Server→Databases→Tables→Rows→Columns
Elasticsearch:Node→Indices→Types→Documents→Fields
註:indices 是 index 的複數。
另外,Elasticsearch 是使用 JSON 的巢狀結構,不是二維表格。
安裝 Elasticsearch
這裡以 Linux 環境為例。不過 Windows、Mac 都有相對應版本。
Elasticsearch 是用 Java 寫的,所以執行環境需要有 jre。
apt-get install openjdk-7-jre
接著到 Elastichsearch 的下載頁面取得最新版本的連結(一般來說選 tar.gz 版本),之後用 wget 下載下來,例如:
wget https://download.elasticsearch.org/elasticsearch/release/org/elasticsearch/distribution/tar/elasticsearch/2.1.1/elasticsearch-2.1.1.tar.gz
接著解壓縮(記得把2.1.1替換成你下載的版本)。
tar zxf elasticsearch-2.1.1.tar.gz
切換到 elasticsearch 目錄後,可以直接執行 Elasticsearch。
./bin/elasticsearch
也可以加上 -f 選項讓 Elasticsearch 在後台運作。
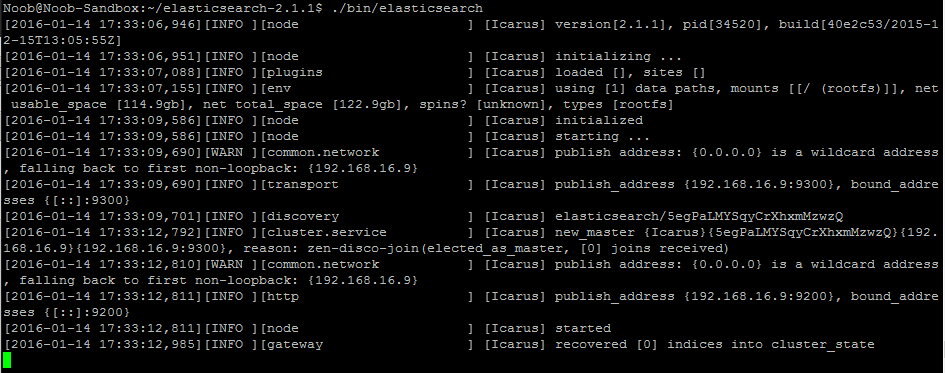
操作 Elasticsearch
看到 Started 字樣後,就代表 Elacsticsearch 已經啟動完成。由於 Elasticsearch 是用 Java 寫的,當然有提供它的 Java API,不過在這邊我還是選擇用比較簡單的 RESTful API 來操作。
- 到這裡不懂 RESTful API 沒關係,只要知道等等可以用 curl 來操作就好。不過,你還是看一下什麼叫做 HTTP Method 好了:淺談 HTTP Method:表單中的 GET 與 POST 有什麼差別? – Soul & Shell Blog
- Elasticsearch 預設開啟的 port 是 9200,有需要的話可以到 config/elasticsearch.yml 來修改。
操作 Elasticsearch 的格式基本上是這樣:
curl -X<method> ‘http://<server>:<port>/<index>/<type>/[<id>]
接著來試著新增一些資料到 Elasticsearch 上吧!例如我們建立一個 twitter 的 user (Elasticsearch 會自動幫我們建立索引):
curl -XPUT 'http://192.168.16.9:9200/twitter/user/Noob?pretty' -d '{"name": "Noob"}'
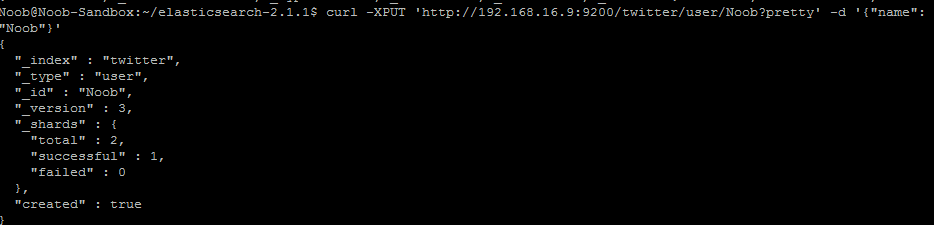
?pretty 是什麼?你可以不要加試試看,加了只是會讓它回應的排版變比較美而已 XD
可以用 GET 方法來取得資料,例如:
curl -XGET 'http://192.168.16.9:9200/twitter/user/Noob?pretty'

既然叫做 Elasticsearch,最重要的應該還是搜尋吧?一樣是用 GET 方法,如果你有多筆資料,你可以這樣搜尋:
curl -XGET 'http://192.168.16.9:9200/twitter/tweet/_search?pretty'
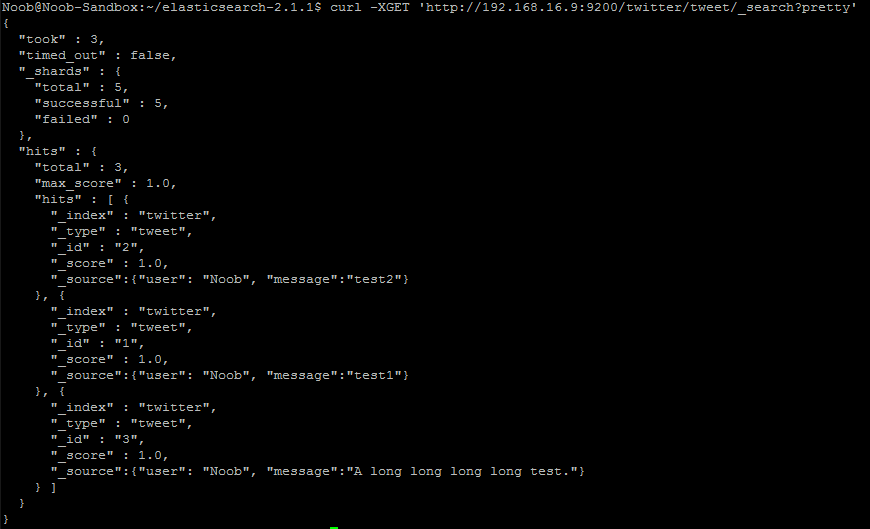
這些回傳的資料都是巢狀的 JSON 格式,會很好處理。當然還有其他搜尋的方式,可以參考官方文件看看。
最後,如果對 Elasticsearch 有興趣,可以看看 GitHub 上的文件:elastic/elasticsearch。